近日,机器学习与人工智能领域国际学术会议International Conference on Machine Learning(ICML 2026)录用结果正式公布。我校信息学院模式分析与机器智能团队共有两篇学术论文被会议接收,实现了在该顶级会议上的重要突破。
ICML是机器学习与人工智能领域最具影响力的国际会议之一,同时也是中国计算机学会(CCF)推荐的A类会议。在本次录用的两项成果中,我校2025级硕士研究生王阿康、余书文分别为两篇论文的第一作者,户战选老师为通讯作者,云南师范大学为主要完成单位。相关研究围绕机器学习与人工智能前沿问题展开,体现了团队在该领域持续深入的研究能力与创新水平。
【成果一】基于视觉语言模型的多标签图像识别
王阿康同学发表了题为“[CLS] is Not Enough: Multi-Label Recognition via Patch-Level Inference and Adaptive Aggregation”的研究论文。
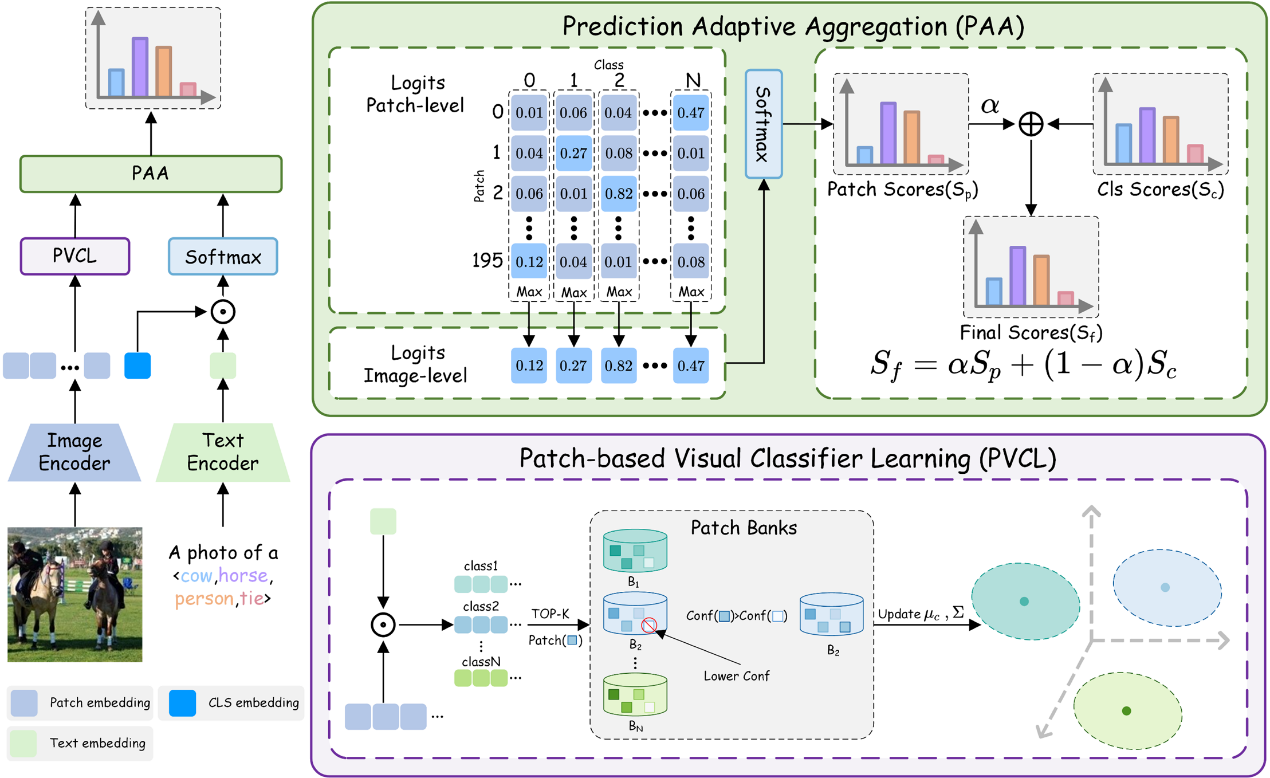
在视觉-语言大模型(VLM)快速发展的背景下,CLIP等先进模型展现出了卓越的零样本识别能力,但其过度依赖单一的全局[CLS]标记,难以处理多尺度、多目标共存的复杂图像。针对这一问题,该研究团队创新性地提出了一种全新的多标签图像识别框架。该框架创造性地将识别过程划分为“补丁级推理”与“自适应聚合”两个阶段,有效缓解了特征提取中的语义纠缠,并进一步缩小了跨模态差距。测试结果显示,该方法在完全免训练、计算开销极低的情况下,在极具挑战性的基准数据集上实现了高达6%mAP(平均精度均值)性能提升,为多标签图像识别领域提供了全新的高效解决方案。
【成果二】异构基础模型无监督几何对齐
余书文同学发表了题为“Geometry-Preserving Unsupervised Alignment for Heterogeneous Foundation Models”的研究论文。
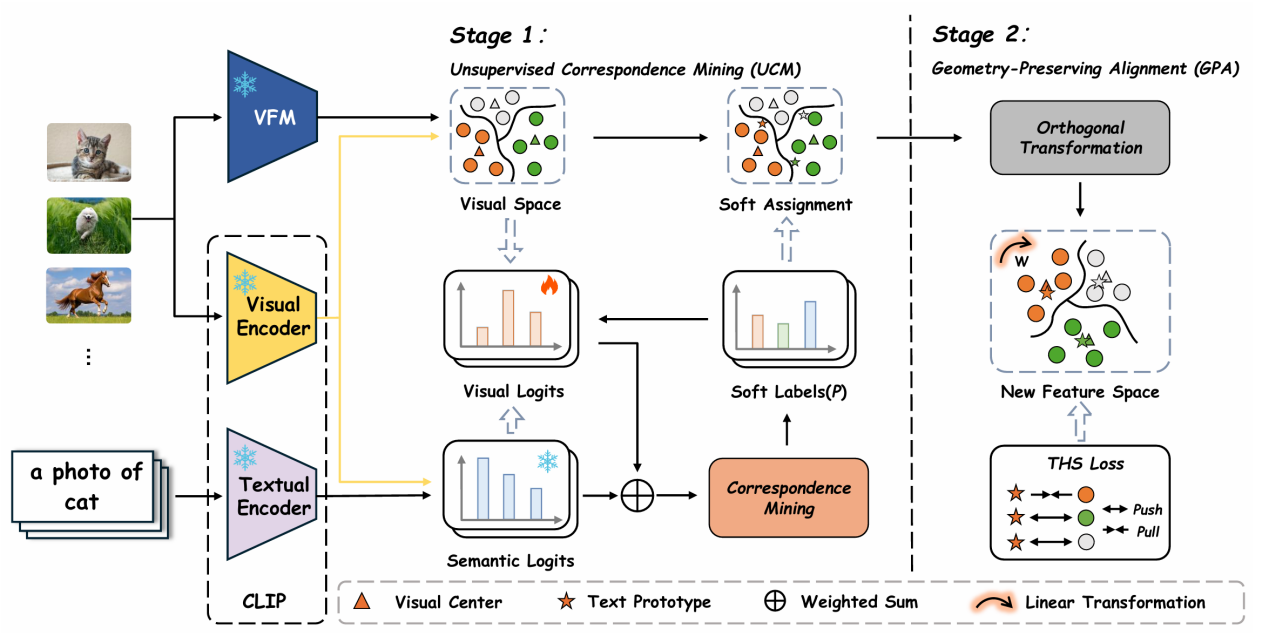
该研究紧密聚焦于异构基础模型空间中的无监督几何对齐问题。研究团队发现,传统单一模型在视觉语义表达中往往依赖粗粒度特征,难以准确表征局部复合目标,精细化感知能力存在明显不足。为此,团队引入异构基础模型协同机制,提出了一种几何保持的无监督对齐框架GPUA,通过融合视觉基础模型与视觉-语言模型的互补优势,实现跨模型特征空间的高效映射与对齐。该框架无需标签、参数微调或梯度优化,即可完成完全免反向传播的推理过程,同时有效保留视觉几何结构并缩小模态差距。实验结果表明,该方法在多项具有挑战性的基准数据集上均显著优于经典基线模型,对推动多模态基础模型的统一融合与精细化空间对齐具有重要的理论意义与应用价值。
(信息学院 供稿)



